Unraid has been a critical piece of storage infrastructure in my homelab for some time now. I mainly use it for Proxmox backups and personal file storage.
After perusing my file structure and finding a few duplicate files that were consuming quite a bit of array space, I decided to investigate how I could holistically scan my entire array and generate a listing of all duplicate files and their sizes.
There isn’t a great way to do this natively within Unraid. I figured this had to be a somewhat common problem, and there is probably already a feature-rich solution out there that I could leverage instead of writing my own script. And so I found Czkawka.
What is Czkawka?
The project’s GitHub README does a pretty good job of describing the software: Czkawka is a simple, fast and free app to remove unnecessary files from your computer. Most importantly to me, it provides a simple implementation of a file scanner that can enumerate all files in a given directory, compute their hashes, and find duplicate files.
One thing I noticed right away is that it’s GUI based, a development choice which might ruffle some feathers, but I figured I’d give it a shot anyway. Read on below for a walkthrough of how I deployed this in Unraid and used it to find duplicate files in my array.
Deploying Czkawka
I prefer to deploy tools like this as Docker containers instead of installing a software and all of its dependencies directly on my hosts. Luckily, a pre-built container already exists that we can use: jlesage’s docker-czkawka.
I chose to run this container directly on my Unraid server. This isn’t my standard procedure for instantiating containers - I prefer to host any compute workloads on Proxmox nodes, but since the sole purpose of this container is to scan the Unraid file system for duplicate files, I chose to deploy on Unraid itself. This eliminates any network overhead associated with remotely reading files over the network.
To get started, download the Czkawka app by Djoss from the Unraid app store and spin up a new container using the image.
Container settings
When you’re configuring the container, the most important setting is the Storage Path. Make sure that this variable is set to the directory containing whatever files you are trying to deduplicate. Docker will expose this directory to the container when it’s instantiated. In my case, I want to use /mnt/user as that is the default location for all Unraid file shares.
There are some other settings of interest available in the Docker config which you can choose to modify depending on your use case. Some ones that you might want to take a look at include:
USER_IDandGROUP_ID- may be necessary to change these depending on the permissions of the files to be scanned.APP_NICENESS- controls the processing priority of the Czkawka process. Settings this to a negative number increases the priority of the scanning process, and setting it to a higher number decreases the priority.DARK_MODE- enables the dark mode theme for Czkawka.WEB_AUTHENTICATION- if set to 1, requires a login before accessing the application’s WebUIWEB_AUTHENTICATION_USERNAMEandWEB_AUTHENTICATION_PASSWORD- username and password for web authentication, if enabled.WEB_LISTENING_PORT- the TCP port that Czkawka listens on. By default, this is set to 5800WEB Port for GUI (Bridge Network Type)- if you’re using the Bridge network type in your Docker config, this port will be used for accessing the web application instead of theWEB_LISTENING_PORT. Default is 7821
Using Czkawka
Now that the container is created and listening on the configured port, the web application is accessible at [unraid.local]:7821. It should look something like the screenshot below.
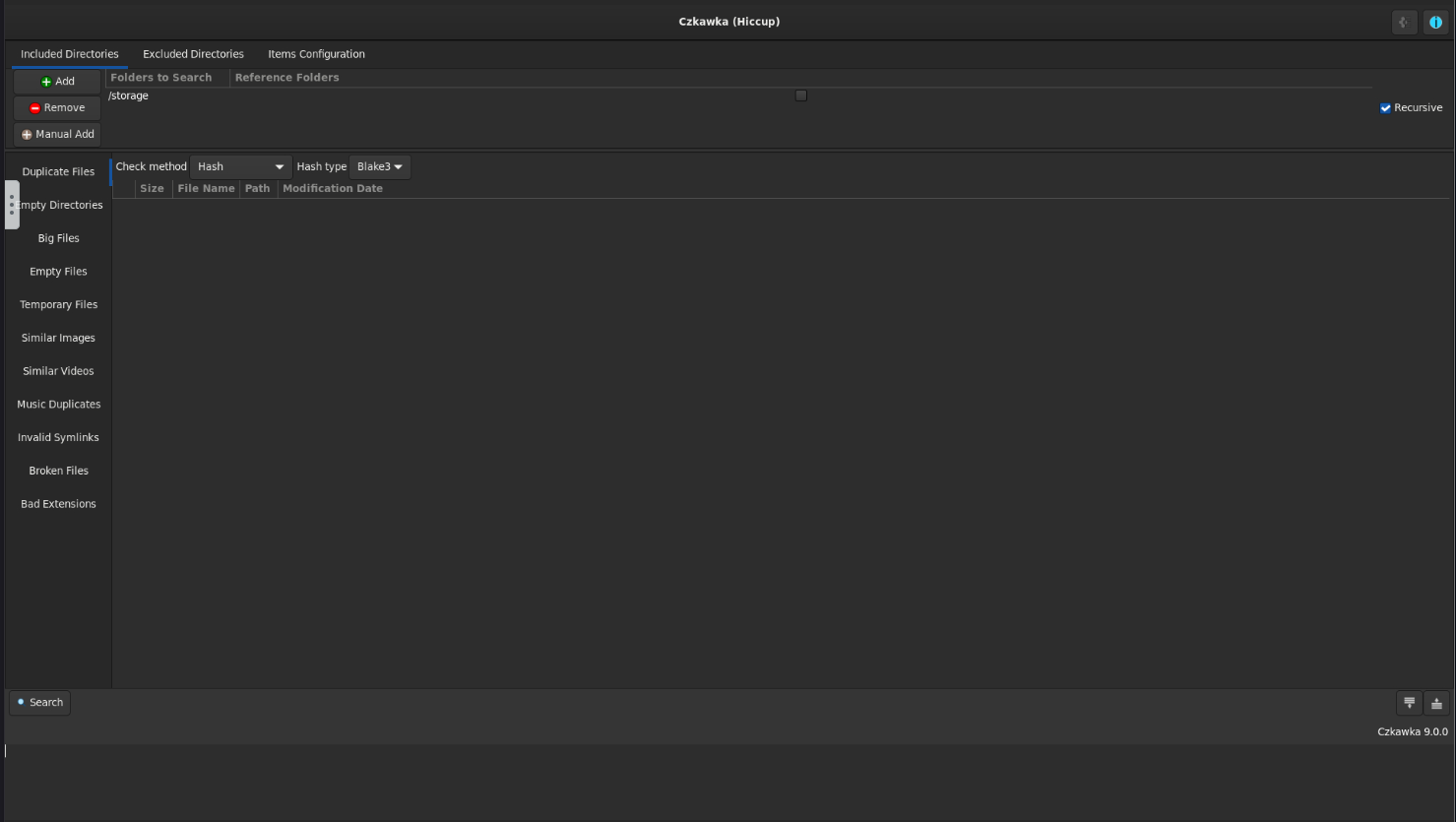
You’ll notice that there’s only one folder to search defined in the top UI pane - “storage”. This directory in the container maps to whatever directory you defined in the Docker configuration.
Starting a scan
Warning
Czkawka determines if files are duplicates by computing and comparing their hash values. Depending on your hardware and the size of the array that Czkawka is scanning, this can be quite taxing on the system. I would not recommend running a scan when other computationally intensive tasks are being performed on the system.
To get started with scanning the filesystem for duplicates, make sure you have the “Duplicate Files” scan type select on the left, and then click the “Search” button in the bottom left of the UI. This kicks off the scan, and a nice progress bar will appear giving you an idea of the scan progress.
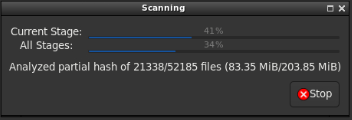
And here’s a snapshot of what my Unraid server’s resource consumption looked like during the scan.
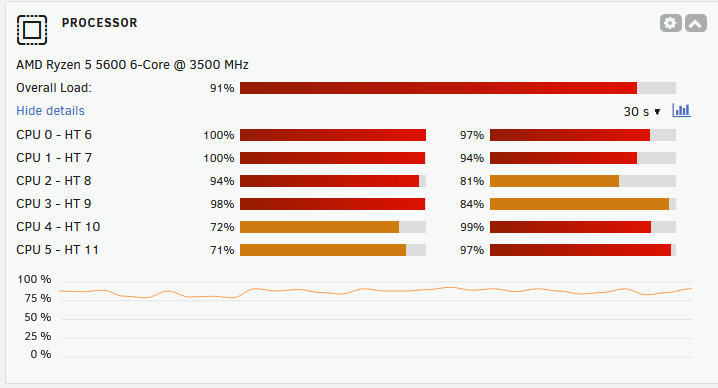
The system usually idles at ~10% CPU utilization. As you can see, the scanning process is consuming most of the system’s CPU cycles. If this concerns you, you can try messing with the APP_NICENESS setting to deprioritize the scanning process, or use Docker resource constraints.
In my case, scanning ~13.8 TB of data stored on 7200 RPM SAS drives with a Ryzen 5600 took about 1 hour and 24 minutes.
Using scan results
When the scan is completed, you’ll see an output that looks something like the screenshot below (file names redacted for opsec).
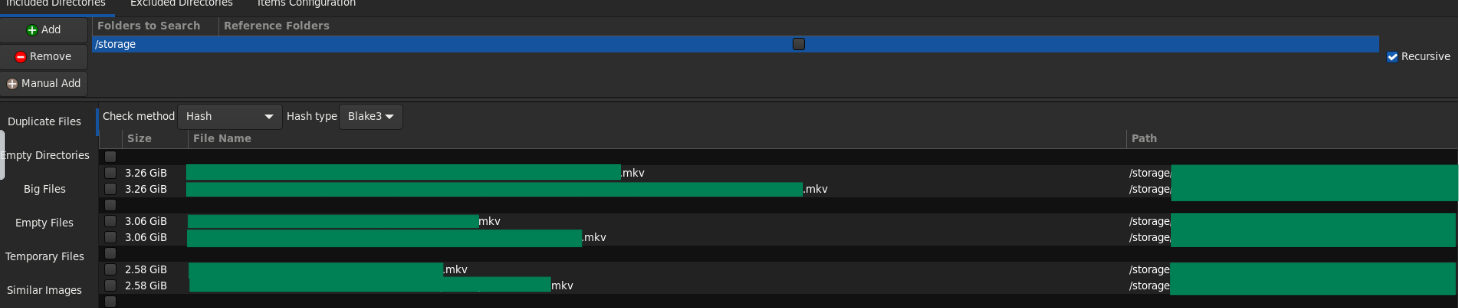
In this example, you can see that I have three duplicate files of varying sizes. Now I can either remove the files manually through the terminal or use the “Delete” button in the Czkawka UI to remove the duplicates through the application. You can also use Czkawka to deduplicate files by creating symlinks or hardlinks for duplicate files, if you prefer. Though for my use case, deleting the duplicates accomplished my goal of reclaiming disk space on my array.
Czkawka also supports various other file analysis functions that you can use to find files and folders of interest, such as:
- Empty directories
- Big files, empty files, and temporary files
- Visually similar images and videos
- Duplicate audio files
- Invalid symlinks
- Invalid or corrupted files
- File extension mismatches
For more info on this program, see the project’s GitHub repo.